Parsing is hard
I’ve been trying to write a text-based Scratch editor for years now. My earlier attempts weren’t called “tosh”, but they were prototypes of the same idea.
The hard part is turning text into Scratch blocks. I have to do two things:
design the syntax: what should the text look like?
At first I based my prototypes on scratchblocks syntax, since it would be familiar to my users.
implement the parser: the program that extracts the structure of the text, to turn it into Scratch blocks.
Inspired by Parsing: The Solved Problem That Isn’t, I’m going to describe the different approaches that I tried, and why they’re terrible. This will give you a general overview of parsing.
(I’ll write more about syntax soon.)
Construct
I wrote Kurt, which lets you manipulate Scratch projects using Python code. Scratch 1.4 projects have a crazy binary file format, so Kurt uses Construct to make encoding and decoding much easier.
Construct is a binary parsing library, which it’s very good at.
It’s declarative, so you write a description of the binary format, and it handles encoding and decoding for you. Here’s a simple structure:
c = Struct("foo",
UBInt8("bar"),
SLInt16("quxx"),
LFloat32("garply"),
)
Construct could also parse text, which it was not very good at.
The FAQ said:
What isn’t Construct good at?
As previously mentioned, Construct is not a good choice for parsing text, due to the typical complexity of text-based grammars and the relative difficulty of parsing Unicode correctly. While Construct does have a suite of special text-parsing structures, it was not designed to handle text and is not a good fit for those applications.
I tried to use it anyway. Have a look at the awful code if you want.
To parse text, you need to be able to deal with alternatives. Construct had a
Select class for describing alternatives. It worked by trying each
subconstruct in turn, and returning the first one that didn’t raise an error.
So you could write something like:
c = Struct("foo",
Select("insert",
Sequence("predicate",
Literal("<"),
predicate_block,
Literal(">"),
),
Sequence("reporter",
Literal("("),
reporter_block,
Literal(")"),
),
)
It turns out that this is not a good way to specify the syntax of a language. Things didn’t always work, and the code got messy.
Bryce Boe suggested I look into “lex/yacc”, telling me it’s what most people use.
Parser theory in four hundred words
Time for some terminology!
Parsing is all about getting structure out of text. It’s how Python
transforms a statement like print 2 + sin(6) * 4 into a parse tree which
looks something like this:
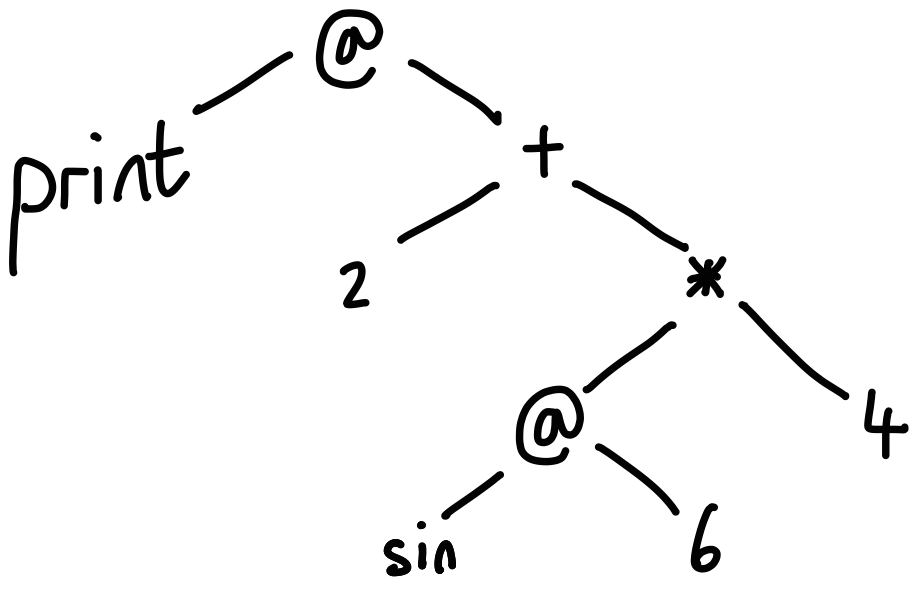
Tokenizing
Most of the time, there’s a separate tokenizing stage that happens before
parsing. It does a first pass over the text, splitting it up into a list of
tokens. For example, the input if <(score) > (12)> might become:
SYMBOL "if"
LANGLE "<"
LPAREN "("
SYMBOL "score"
RPAREN ")"
LANGLE "<"
LPAREN "("
NUMBER "12"
RPAREN ")"
RANGLE ">"
This list of tokens is then used as input to the parser.
Not all parsers do this. Some parsers skip the tokenizing stage, and operate on a list of characters. This is called scannerless parsing: it doesn’t fit my use case, so I’ve never used it.
Parsing
You describe the syntax of a language using a context-free grammar, which is a set of rules describing how to build each node in the parse tree.
Consider the input say "Hello!" for 10 secs. To parse this successfully, we need to see the following tokens:
- the word
say; - a string;
- the word
for; - a number;
- the word
secs.
We can express this using the following CFG rule:
block -> "say" TEXT "for" NUMBER "secs"
On the left we write the name of the rule. On the right is a list of
tokens (or other rules; we’ll see that in a second). This describes how to
build a block node in the parse tree.
By convention, names in UPPERCASE are tokens; names in lowercase refer to
other rules. I write tokens for word tokens like “say” in quotes, instead of
upper case.
But that’s not quite right. We want to allow reporter blocks inside inputs, as
well as constants like 10. Let’s extend our grammar:
block -> "say" text "for" number "secs"
text -> TEXT
| "join" text text
number -> NUMBER
| number "+" number
The pipe character | is syntax for writing alternatives: to build a text
node, we can either parse a TEXT token, or a "join" token followed by two
more text nodes.
Now we can parse inputs like:
say join "Hello " "world!" for 2 + 3 secs
By building larger rules out of smaller ones in this way, we can describe the entire syntax of the language.
For more, have a look at the Wikipedia page for EBNF (which is a way of specifying context free grammars).
PLY
lex is a tokenizer (or “lexer”). To use lex, you tell it what each kind of token looks like. For example, you specify that number tokens contain one or more digits, and may contain a period.
yacc is a parser generator. You give yacc a CFG, and it spits out a heavily-optimised parser. This parser takes the tokens from lex as input, and returns the parse tree.
I used PLY, a Python implementation. You can see the complete parser I wrote.
The trouble with yacc is that to be efficient, it doesn’t accept any context-free grammar. The grammar must be in a special form called LALR. LALR is hard to define: the best definition is a circular one, ie. “yacc can parse it”!
This places restrictions on the kind of production rules that you can write. These restrictions are mostly artificial: humans don’t naturally write LALR grammars.
Recursive descent
Recursive descent seems to mean “write the parser by hand”. You must define a function to parse each production rule. They’re incredibly tedious to write, and can have problems with backtracking.
Despite that, they are essentially the state-of-the-art in parsing: most programming languages in wide use today have hand-written parsers. That’s crazy!
Some languages don’t even have a formal specification using CFGs, which is a problem when trying to implement new parsers for those languages.
I didn’t try recursive descent, because I’d have to write a function for every block in Scratch.
New syntax
At this point I realised scratchblocks syntax was a bad idea. It’s awkward to write, as well as difficult to parse. This is why I try to make clear that tosh is not scratchblocks.
This was mostly inspired by my friend Nathan-from-the-internet. He wrote:
I wrote a scratchblocks parser that is reasonably skilled at determining what you mean without hordes of parentheses (e.g.,
set a to item 2 + 3 * 4 of positions + 10instead ofset [a] to ((item ([2] + ([3] * [4])) of [positions v]) + [10])) …
So I changed my design: I wanted to minimise parentheses, and make a language that’s actually pleasant to write; while keeping the idea that you can write code as you would read Scratch blocks.
Of course, this new language is even harder to parse.
TDOP
Top-down operator precedence is a neat parsing algorithm, so I tried that next. Maybe it would solve all my problems?
TDOP doesn’t use CFGs directly; it attaches parsing logic directly to each token. As the name suggests, it’s good at handling precedence, so it works well for infix expression grammars.
Unfortunately it didn’t work well for my prototype, since word tokens like
set can have multiple meanings. I wrote a bunch of code to keep track of
possible blocks based on the tokens seen so far, but it ended up growing so
large it almost took over from the TDOP part.
The TDOP-based parser is included in Kurt, and you can try it using the Text Parser tool.
It mostly works, but there are some valid inputs which it can’t parse. It’s hard to work out how to fix these, because it’s hard to reason about how the code relates to the grammar.
Earley
I mentioned that parsing is not a solved problem.
So far we’ve seen:
- Binary parsing does not extend well to text parsing (whoops).
- CFGs are a nice way of defining grammars.
- yacc is fast, but places restrictions on your grammar.
- TDOP is neat, but hard to reason about.
- Hand-written code is the state-of-the-art.
What I really wanted was an algorithm that could take an arbitrary context-free grammar and parse it efficiently. I didn’t want weird restrictions like LALR-ness, and I didn’t want to write code by hand.
Fortunately, such parsers exist! One of them is Earley’s algorithm. I discovered Earley’s via my friend Kartik, who wrote an Earley parser in Javascript.
He also wrote an explanation of Earley parsing. Earley parsing is going to be pretty important for what follows, so I may have a go at explaining it myself.